
A few weeks ago I hit my six-year anniversary at Microsoft. In that time, I've worked with several teams building web services inside the company, and I've built a network of decent size at many of our peer companies. I've learned a lot about software engineering, both from my own experience and that of my peers. In all this time, perhaps the biggest thing I've understood is this: pretty much every engineer who works on a software project of any complexity hates their codebase.
Talented engineers faced with market pressures make tough choices that almost miraculously result in shipped software. It's well understood that those choices add up at a micro level as technical debt, and most great companies have figured out mechanisms for improving individual components over time. But it's harder to account for—and correct—choices that add up at a macro level.
Architectural debt is the sum of those macro-level choices. It affects every piece of your code base, and is usually the result of decisions that were made years ago. Importantly, those decisions may well have been the right ones at the time, both from a "getting to market" perspective and from a "right technical choice for this moment in time" perspective.
However, because it affects so much of your codebase, it's dramatically harder to revisit architectural debt, and the decisions that made sense once upon a time evolve into an albatross around the neck of the people who have to deal with them now. This is the source of the codebase hatred that pervades among engineering departments at companies; they are weighed down by two major factors:
- The architectural debt has started affecting every aspect of their day-to-day work: everything takes a long time, functionality is fragile, ownership and accountability is hazy, etc.
- The codebase is so large that making any real impact on the problem seems like an insurmountable challenge.
One of the most common manifestations of architectural debt that services are particularly vulnerable to is that your codebase grows up to be a single, giant, interwoven monolith. These monoliths exhibit both of the aforementioned problems in spades:
- It's hard to test a piece of software where dependencies and interfaces aren't well defined, so one developer can often break hundreds of others.
- Developers will have moved around the company and changed ownership until no one is really clear on who is responsible for what piece of code (or the nominally responsible people aren't the ones with the knowledge to actually fix it).
- Finally, the sheer size of the codebase means that the speed of everything from builds to deployments inevitably slows to a crawl.
Lots of literature has been written on the pitfalls of monoliths, and the usual proposal for fixing them is to rearchitect your complicated codebase into a whole new pattern: microservices, a collection of small, independent services with a well-defined role, a well-defined association to a specific team, and a well-defined set of interfaces to all the other services that make up your product.
This structure is not without its own pitfalls and tradeoffs, as you now have to worry about forward and backward compatibility across many more interfaces, latency, etc., but for sufficiently complex products with sufficiently large numbers of developers, the benefits of small groups of developers becoming empowered to control their own destiny and make independent progress pretty clearly outweigh those costs.
When an engineer is shown the possibility of the promised land—of being able to check in and ship his flawless code without those jerks in another hallway holding him up—he may decide, "Okay, let's make this happen!" But how?
The soccer ball approach
Frequently, the first attempt engineers make at an approach to moving from a monolith to microservices goes something like this:
- Catalogue the functionality of everything in the monolith.
- Attempt to group chunks of functionality into roughly similar-sized, substantial pieces of code that can serve as microservices, and figure out what the interfaces between them might look like.
- Realize, upon looking at the code, that the components are so entangled that the first pass at grouping isn't functional, and repeat step 2.
- Continue repeating steps 2 and 3 until coming to either the realization that the only way to carve all those substantial components from the monolith is to send a half dozen of your best developers off into a conference room to focus on this problem full-time for six months and pray for the best, or to sign up for a rewrite of much of your codebase.
The proposals produced in this model look somewhat like a classic soccer ball:
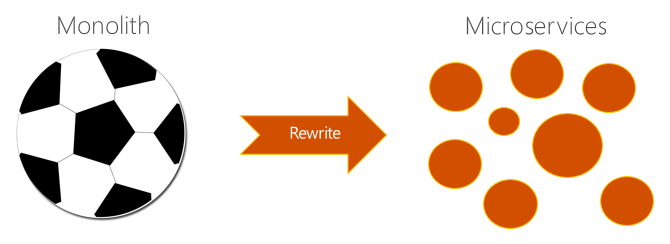
The reason this approach almost inevitably leads to analysis paralysis is the same as the second major factor that makes engineers hate their codebase above: making any real impact on this problem seems like an insurmountable challenge. And it's awfully tough to sacrifice several man-years of your best developers on a major refactoring project which may or may not be successful, let alone a full-fledged rewrite, when your competitors continue to put out new features that make you feel like you're falling behind.
Ultimately, the end result of this approach tends to be a few minor improvements to the structure of your codebase, and a deep, despondent feeling of resignation as you kick the problem down the road another year. In particularly unhealthy situations, engineers might conclude that the product managers just don't understand or care about the architectural debt that's causing them so much pain, because their pitch for a full rewrite goes ignored.
Thankfully, there's a better way.
The solar system approach
While defining a comprehensive rearchitecting of your codebase is risky and intimidating, defining one or two smallish pieces of your service that meet the criteria to become a microservice (well-defined role, accountability and interfaces) is imminently possible. In fact, even in the most monolithic of architectures, you generally find a few intrepid teams who've found a way to isolate their own code from the rest of the monolith and start accruing some of the benefits of controlling their own destiny.
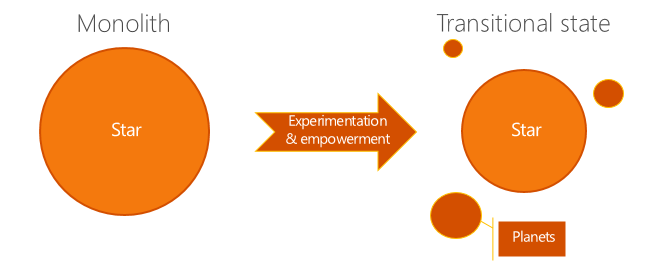
In the solar system model, rather than trying to define a complete set of components and set teams off to decouple things in accordance to your grand new architecture, small teams gradually carve out pieces of your monolith when the churn on those pieces is significant, and engineer them using a new set of tools optimized for much smaller codebases.
What you end up with is a "star" monolith, which shrinks slowly over time as engineers spin off new "planets": their own microservices that "orbit" the star, providing it with essential services. You might add more planets as organizational changes or small pieces of new functionality come online, until you end up in a transitional state where you still have a significant chunk of your code living in the star, but 40-50% of your developers' day-to-day jobs are dealing with planets and their faster, lighter-weight processes. 500px's architecture is a great example.
The key consideration in the solar system model is that there's a second, more substantial cause for the shrinking of the star: the natural evolution of your product. Unlike early software projects, most mature projects don't add new features linearly: many of the new features are straight-out replacements for legacy functionality. As these new features are written, the engineering team can and should write them using the new, preferred microservice pattern from the start. And as they come online and mature, the old features can be deprecated and removed—further shrinking the remains of the monolith.
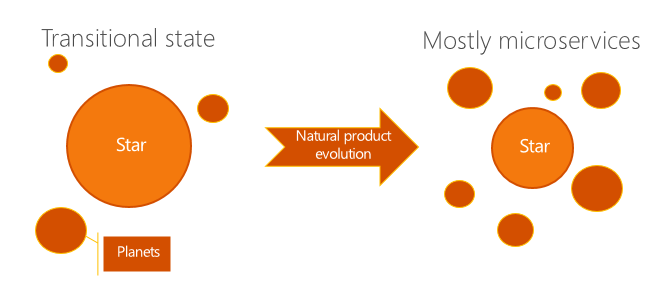
Ultimately, you might indefinitely have a star that's an order of magnitude larger than any of the planets in your codebase. But if the code remaining in that star needs to be updated infrequently and nearly all of your developers spend 90% of their time working in the world of the planets, you've largely solved their productivity problems.
Now, there is a clear tradeoff to this approach: you're relying on a sustained effort to do the right thing over a long period of time (as one example, Wix took 4.5 years to go from a monolith to over 100 microservices), and fewer engineers get to benefit from working on small components early on. But the game-changing benefit is that this approach is actually dramatically more likely to be successful.
Forming a solar system
If you do embark on a many year effort to form a solar system around your monolith, you have to consider that a microservice architecture isn't automatically going to solve all of your problems: you are just trading a new set of problems for your old ones.
These problems can range from performance, as you potentially introduce network hops between individual services, to dependency hell, where any core API change still takes months or years to roll out because so many individual services have dependencies on it and they don't all update on the same cadence. The bet is that the new set of problems is solvable, though, and the scalability of hundreds of engineers working on one tightly-coupled codebase is not.
Importantly, you can put in place a substrate of horizontal functionality that helps teams authoring new microservices make the right decisions and play nicely with the rest of your service. That substrate may include everything from ensuring that logging is consistent and a single transaction can be traced across all of your microservices, to handling the rollout of new functionality to a small set of customers and lighting up a consistent experience delivered by many services at once. In the solar system world, teams must find doing things the right way is the path of least resistance, lest they give in to the temptation to build more things in the monolith the way they're already used to.
At the end of the day, neither of these approaches is rocket science; lots of companies and experts have independently discussed successes and failures with both big-bang and gradual migrations from monolithic to microservice architectures.
But there's power in naming things: it gives passionate engineers the terminology to use to advocate for (or against) an idea. In discussions that affect the day-to-day happiness of hundreds of your best engineers, you need every bit of leverage you can get. So here's my stake in the ground: the solar system approach is the right way to componentize messy, complex software architectures. The soccer ball approach is usually little more than a distraction. I trust you'll make the right choice.